CentOS7 Docker部署ELK(Elasticsearch Logstash Kibana)
需求背景
业务发展越来越庞大,服务器越来越多 各种访问日志、应用日志、错误日志量越来越多,导致运维人员无法很好的去管理日志 开发人员排查问题,需要到服务器上查日志,不方便 运营人员需要一些数据,需要我们运维到服务器上分析日志
ELK vs. Elastic Stack
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。 目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack。 Beats,它是一个轻量级的日志收集处理工具(Agent),占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具.

Elastic Stack包含
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。详细可参考Elasticsearch权威指南
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,Beats所占系统的CPU和内存几乎可以忽略不计。
- Packetbeat: 网络数据(收集网络流量数据)
- Metricbeat: 指标 (收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat: 日志文件(收集文件数据)
- Winlogbeat: windows事件日志(收集 Windows 事件日志数据)
- Auditbeat:审计数据 (收集审计日志)
- Heartbeat:运行时间监控 (收集系统运行时的数据)
准备工作
Docker 安装 请参考CentOS7 下 Docker 升级到最新版本
准备镜像
6.0之后官方开始自己维护镜像版本:https://www.docker.elastic.co/ 。找到需要的ELK镜像地址,pull下来就好了。
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.4.2
docker pull docker.elastic.co/logstash/logstash:7.4.2
docker pull docker.elastic.co/kibana/kibana:7.4.2
官方pull下来之后镜像名太长了,所以我将镜像全部重新打了tag
docker tag docker.elastic.co/elasticsearch/elasticsearch:7.4.2 elasticsearch:latest
docker tag docker.elastic.co/logstash/logstash:7.4.2 logstash:latest
docker tag docker.elastic.co/kibana/kibana:7.4.2 kibana:latest
使用docker images查看,确认是否成功
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.elastic.co/logstash/logstash 7.4.2 642b82780655 3 weeks ago 889MB
logstash latest 642b82780655 3 weeks ago 889MB
kibana latest 230d3ded1abc 3 weeks ago 1.1GB
docker.elastic.co/kibana/kibana 7.4.2 230d3ded1abc 3 weeks ago 1.1GB
docker.elastic.co/elasticsearch/elasticsearch 7.4.2 b1179d41a7b4 3 weeks ago 855MB
elasticsearch latest b1179d41a7b4 3 weeks ago 855MB
安装docker版本ElasticSearch
在elasticsearch的docker版本文档中,官方提到了vm.max_map_count的值在生产环境最少要设置成262144。设置的方式有两种
- 永久性的修改,在/etc/sysctl.conf文件中添加一行:
grep vm.max_map_count /etc/sysctl.conf # 查找当前的值。 vm.max_map_count=262144 # 修改或者新增 - 正在运行的机器
sysctl -w vm.max_map_count=262144之后我们执行命令,暴露容器的9200,9300端口,方便我们在其它机器上可以通过类似head插件去做es索引的操作等。执行命令为:
docker run -p 127.0.0.1:9200:9200 -p 9300:9300 --name elasticsearch -e "discovery.type=single-node" elasticsearch如果实际使用中,可能需要设置集群等操作。因实际情况而定。如果你需要存储历史数据,那么就可能需要将data目录保存到本地,使用-v,或者mount参数挂载本地一个目录。如果实际使用中,可能需要设置集群等操作。因实际情况而定。如果你需要存储历史数据,那么就可能需要将data目录保存到本地,使用-v,或者mount参数挂载本地一个目录。
设置外部目录
在本文实例中采用的就是存储到外部目录,文件系统必须是elasticsearch用户可读。
默认情况下, Elasticsearch 运行的容器内部用户 elasticsearch 的 uid:gid 是 1000:1000.
mkdir esdatadir
chmod g+rwx esdatadir
chgrp 1000 esdatadir
在启动命令中添加参数
docker run -e ES_JAVA_OPTS="-Xms8g -Xmx8g" -d -v /srv/esdatadir/logs:/usr/share/elasticsearch/logs -v /srv/esdatadir/data:/usr/share/elasticsearch/data -p 127.0.0.1:9200:9200 -p 9300:9300 --restart=always --name elasticsearch -e "discovery.type=single-node" elasticsearch
设置JVM堆的大小 使用环境变量
ES_JAVA_OPTS去定义堆的大小. 例如, 设置为 16GB, 在docker run 时加入参数-e ES_JAVA_OPTS="-Xms16g -Xmx16g".
- Elasticsearch 在jvm.options中指定了Xms(最小)和Xmx(最大)的堆的设置。所设置的值取决于你的服务器的可用内存大小。
- 最小堆的大小和最大堆的大小应该相等。
- 设置最大堆的值不能超过你物理内存的50%,要确保有足够多的物理内存来保证内核文件缓存。
安装docker版本kibana
启动kibana
kibana的作用主要是帮助我们将日志文件可视化。便于我们操作,统计等。它需要ES服务,所以我们将部署好的es和kibana关联起来,主要用到的参数是--link:
docker run -d -p 5601:5601 --restart=always --link elasticsearch -e ELASTICSEARCH_URL=http://elasticsearch:9200 kibana
使用link参数,会在kibana容器hosts文件中加入elasticsearch ip地址,这样我们就直接通过定义的name来访问es服务了。
使用Nginx作为反向代理访问kibana
安装httpd-tools
yum install -y httpd-tools
安装nginx,采用nginx官方源安装,详细参考Nginx官方手册
sudo yum install yum-utils
创建源配置文件/etc/yum.repos.d/nginx.repo,并在文件中写入以下信息
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
安装nginx
sudo yum install nginx
创建nginx对应的kibana配置文件
cd /etc/nginx/conf.d/
vim kibana.conf
加入下列参数
server {
listen 80;
server_name elk.bestyii.com; #别忘了改成自己的
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.kibana-user;
location / {
proxy_pass http://127.0.0.1:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
接下来我们为这个访问地址加上个登录授权的账号
sudo htpasswd -c /etc/nginx/.kibana-user bestyii
#输入两边密码就可以了
测试以下配置文件是否正确
nginx -t
确认争取无误后,设置nignx开机启动并启动
systemctl enable nginx
systemctl start nginx
现在我们就可以打开浏览器访问到kibana了。
安装logstash
前面的kibana和ES的安装,如果我们在开发环境中并不需要太多的关注他们的详细配置。但是logstash和filebeat我们需要注意下它的配置,因为这两者是我们完成需求的重要点。
logstash我们只让它进行日志处理,处理完之后将其输出到elasticsearch。
例如我们需要收集系统日志,我们先定义一些设置,保存在外部目录/srv/logstashdir/logstash.conf中,运行docker的时候连接过去方便修改。
input {
beats {
port => 5044
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
注意:hosts的地址,我们用的是
elasticsearch:9200,是因为下面的启动命令是用了--link elasticsearch,前面提到link的作用,所以docker内部会设置hosts。
启动docker版logstash
docker run -d -p 5044:5044 -p 9600:9600 --rm -it --name logstash --link elasticsearch -v /srv/logstashdir/config:/usr/share/logstash/config -v /srv/logstashdir/pipeline:/usr/share/logstash/pipeline logstash
至此服务端已经算是搭建完成了。
在客户端中安装filebeat
客户端安装,可以是docker版本也可以是直接yum安装,这就无所谓了。 本文就采用是yum安装为例。
安装Filebeat
导入elasticsearch key
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
创建源配置文件vim /etc/yum.repos.d/elasticsearch.repo并添加官方源信息
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
安装
yum -y install filebeat
配置 Filebeat
配置文件在本地目录/etc/filebeat中,编辑filebeat.yml
vim /etc/filebeat/filebeat.yml
修改输出的ip地址
output.logstash:
# The Logstash hosts
hosts: ["10.5.5.25:5044"]
接下来, 我们需要启用filebeat modules. 运行 filebeat 命令获取可用 filebeat modules 清单.
filebeat modules list
启用 system module
filebeat modules enable system
filebeat system module 是配合着配置文件modules.d/system.yml使用的 .
我们用的是CentOS系统,所以需要调整一下
vim /etc/filebeat/modules.d/system.yml
我们要监控登录的日志和系统日志
# Syslog
syslog:
enabled: true
var.paths: ["/var/log/messages"]
# Authorization logs
auth:
enabled: true
var.paths: ["/var/log/secure"]
现在就配置好了,启动,并设置开机自动启动。
systemctl enable filebeat
systemctl start filebeat
看一下运行的状态
systemctl status filebeat
在Kibana中测试
登录到 elk.bestyii.com,输入用户名密码,进入到 Kibana Dashboard。
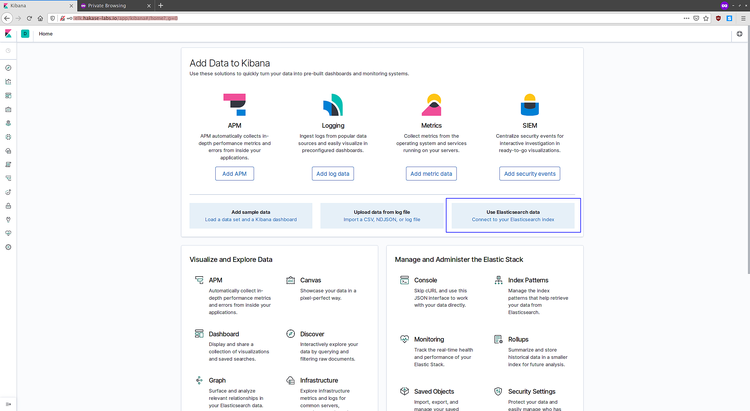
点击 'Connect to your Elasticsearch index',创建索引。
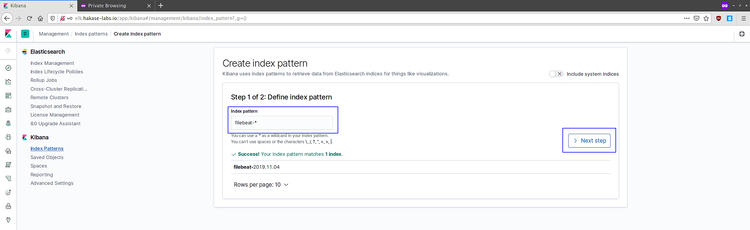
创建 'filebeat-*' 索引规则,并点击'Next step' 按钮。
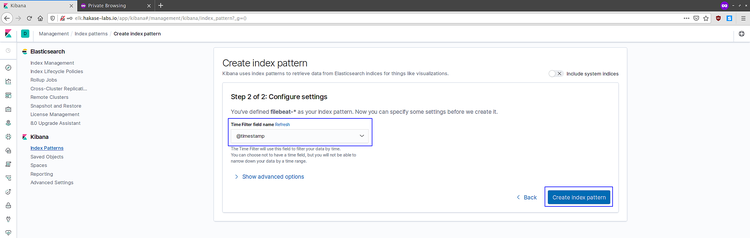
filter name, 选择 '@timestamp' 并点击 'Create index pattern'。
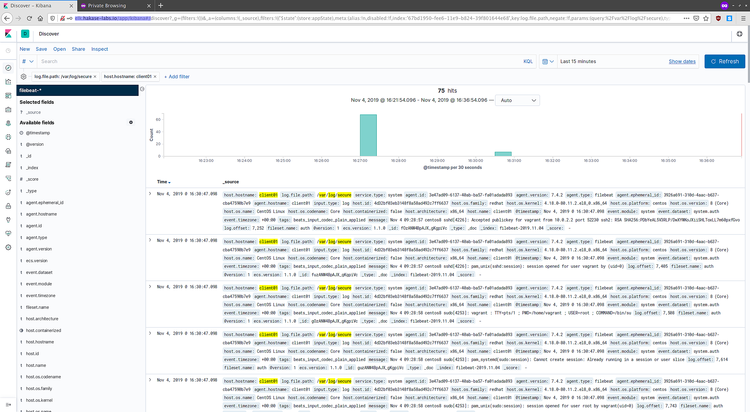
此时 'filebeat-*' 索引规则已经创建完成, 点击 'Discover' 菜单离开。
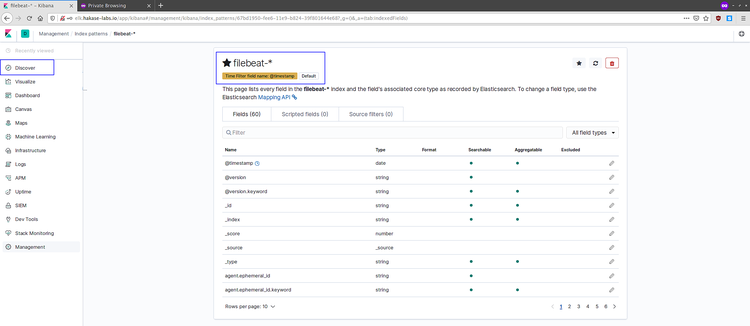
你就可以看到从filebeat发出来的log 数据。
CentOS 7 system Logs
本文由 ez 创作,采用 知识共享署名 3.0 中国大陆许可协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。